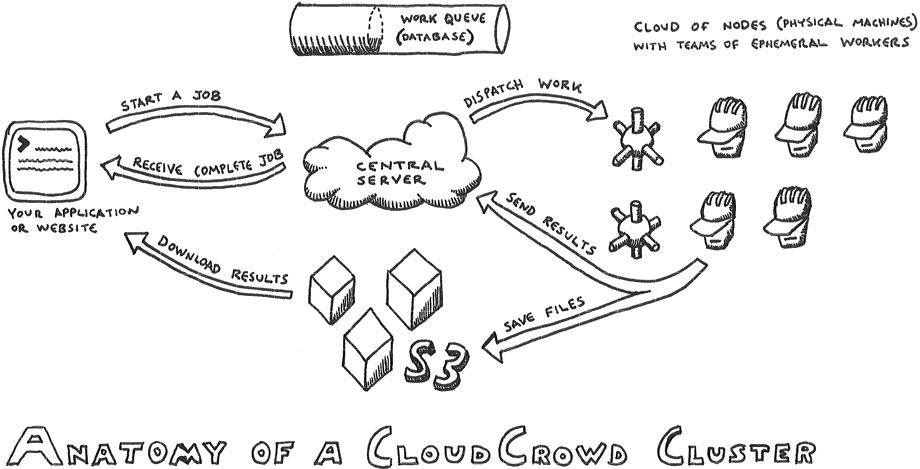
CloudCrowd Architecture
The central server keeps track of the status of all the active jobs and work units, but does not perform any action processing itself. Every split, process, and merge is distributed to a node and run by a worker process. Workers run a single work unit, return their results, clean up their temporary files, and then promptly expire. In this way, when the work queue is empty all the nodes are empty and quiet, and your actions are unable to leak memory over time.
A common bottleneck for distributed processing systems is file storage, which is used to house all intermediate results, as well as inputs and outputs. Google’s original MapReduce uses an in-house distributed filesystem; Hadoop uses the custom HDFS Hadoop filesystem. CloudCrowd uses S3, which makes it a particularly good idea to deploy your CloudCrowd cluster on EC2. Alternative storage support can be plugged into the AssetStore class and selected in config.yml.
These constraints make CloudCrowd appropriate for moderate volumes of highly expensive (for either CPU, memory, or bandwidth) work. The split method allows you to turn a single large file into a highly parallel list of work units, and your nodes will automatically spin up more workers (up to max_workers per node) to handle the job.