A deep learning-based Chinese question classifier (Keras implementation) on BQuLD
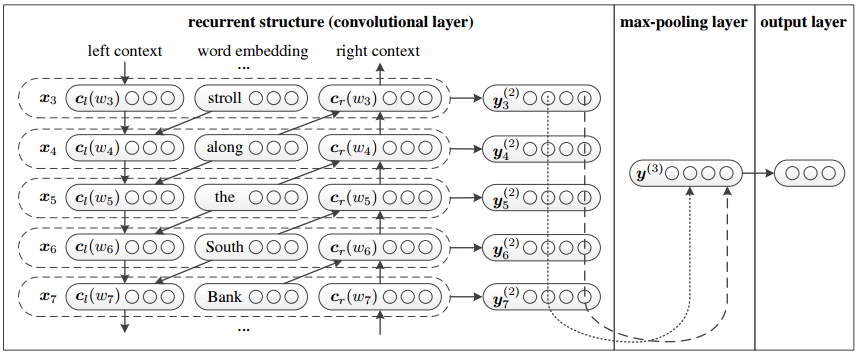
- Model Architecture Overview
- Bilingual Question Labelling Dataset (BQuLD)
- Embedding Preparation
- Result
For more details Click Here.
This dataset is a bilingual (traditional Chinese & English) question labelling dataset designed for NLP researchers.
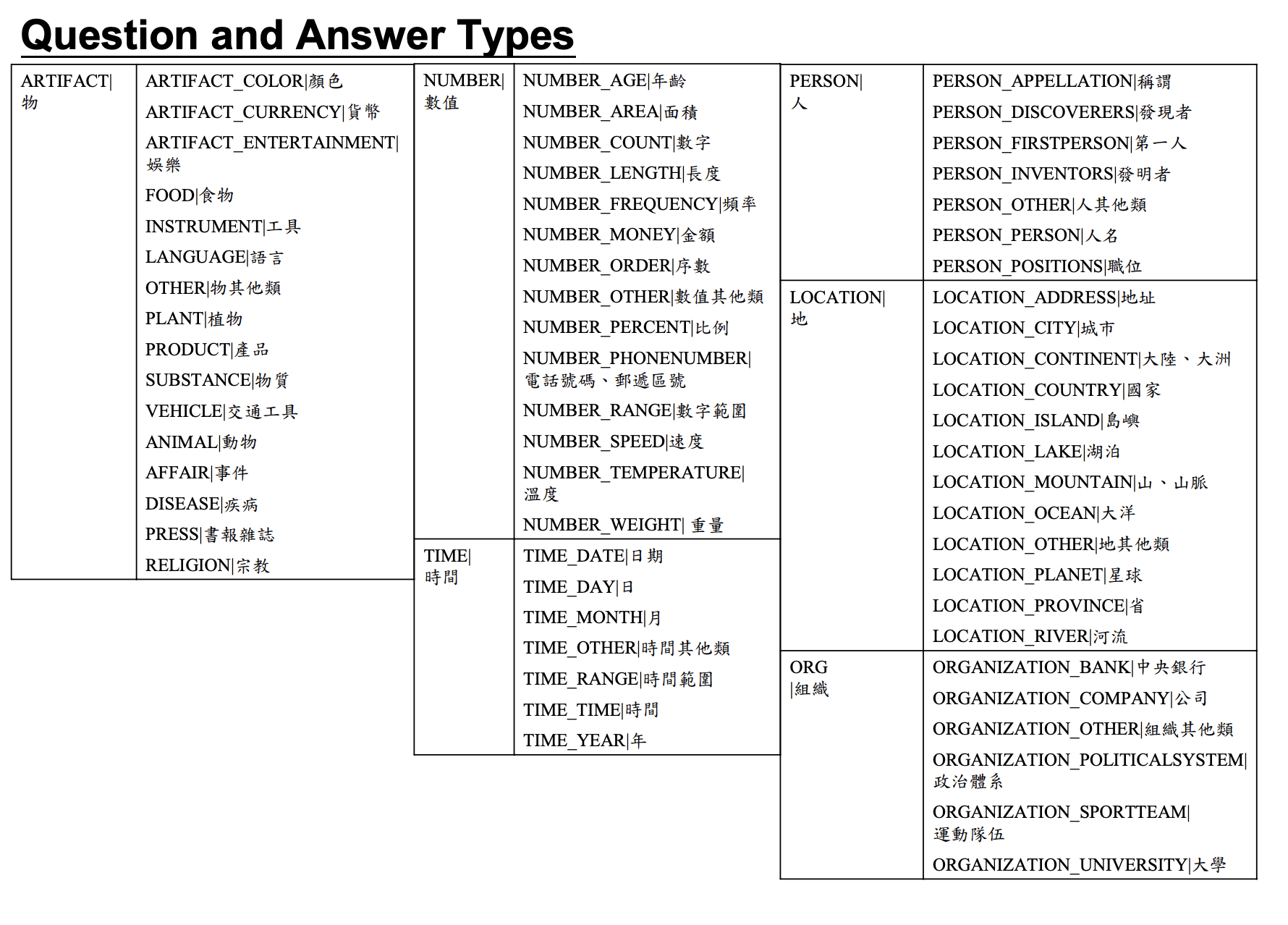
The questinon type definition is borrowed from Intelligent Agent Systems Lab:
The dataset originally consists of 1216 pairs of question and question label, which first published by the author of this GitHub tim5go
There are 9 question types in total, namely:
- NUMBER
- PERSON
- LOCATION
- ORGANIZATION
- ARTIFACT
- TIME
- PROCEDURE
- AFFIRMATION
- CAUSALITY
In my experiment, I built a word2vec model on 全網新聞數據(SogouCA) Sogou Labs
For example, in Linux:
- clean XML tag
$ cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>"
| sed 's\<content>\\' | sed 's\</content>\\' > corpus.txt
- word segmentation using LTP command line
$ cws_cmdline --threads 4 --input corpus.txt --segmentor-model cws.model > corpus.seg.txt
- simplified to traditional Chinese conversion using OpenCC
$ opencc -i corpus.seg.txt -o corpus_trad.txt -c s2t.json
- word2Vec training using Google Word2vec
$ nohup ./word2vec -train corpus_trad.txt -output sogou_vectors.bin -cbow 0
-size 200 -window 10 -negative 5 -hs 0 -sample 1e-4 -threads 24 -binary 1 -iter 20 -min-count 1 &
| Training Loss | Training Accuracy | Validation Loss | Validation Accuracy |
|---|---|---|---|
| 0.7000 | 87.11% | 0.8945 | 77.87% |