{kind=link}
Repository for the RecSys 2021 paper: I want to break free! Recommending friends from outside the echo chamber
Recommender systems serve as mediators of information consumption and propagation . In this role, these systems have been recentlycriticized for introducing biases and promoting the creation of echo chambers and filter bubbles, thus lowering the diversity of bothcontent and potential new social relations users are exposed to. Some of these issues are a consequence of the fundamental conceptson which recommender systems are based on. Assumptions like the homophily principle might lead users to content that they alreadylike or friends they already know, which can be naïve in the era of ideological uniformity and fake news. A significant challenge inthis context is how to effectively learn the dynamic representations of users based on the content they share and their echo chamberor community’s interactions to recommend potentially relevant and diverse friends from outside the network of influence of the users’echo chamber. To address this, we devise FRediECH (a Friend RecommenDer for breakIng Echo CHambers), an echo chamber-awarefriend recommendation approach that learns users and echo chamber representations from the shared content and past users’ andcommunities’ interactions. Comprehensive evaluations over Twitter data showed that our approach achieved better performance (interms of relevance and novelty) than state-of-the-art alternatives, validating its effectiveness.
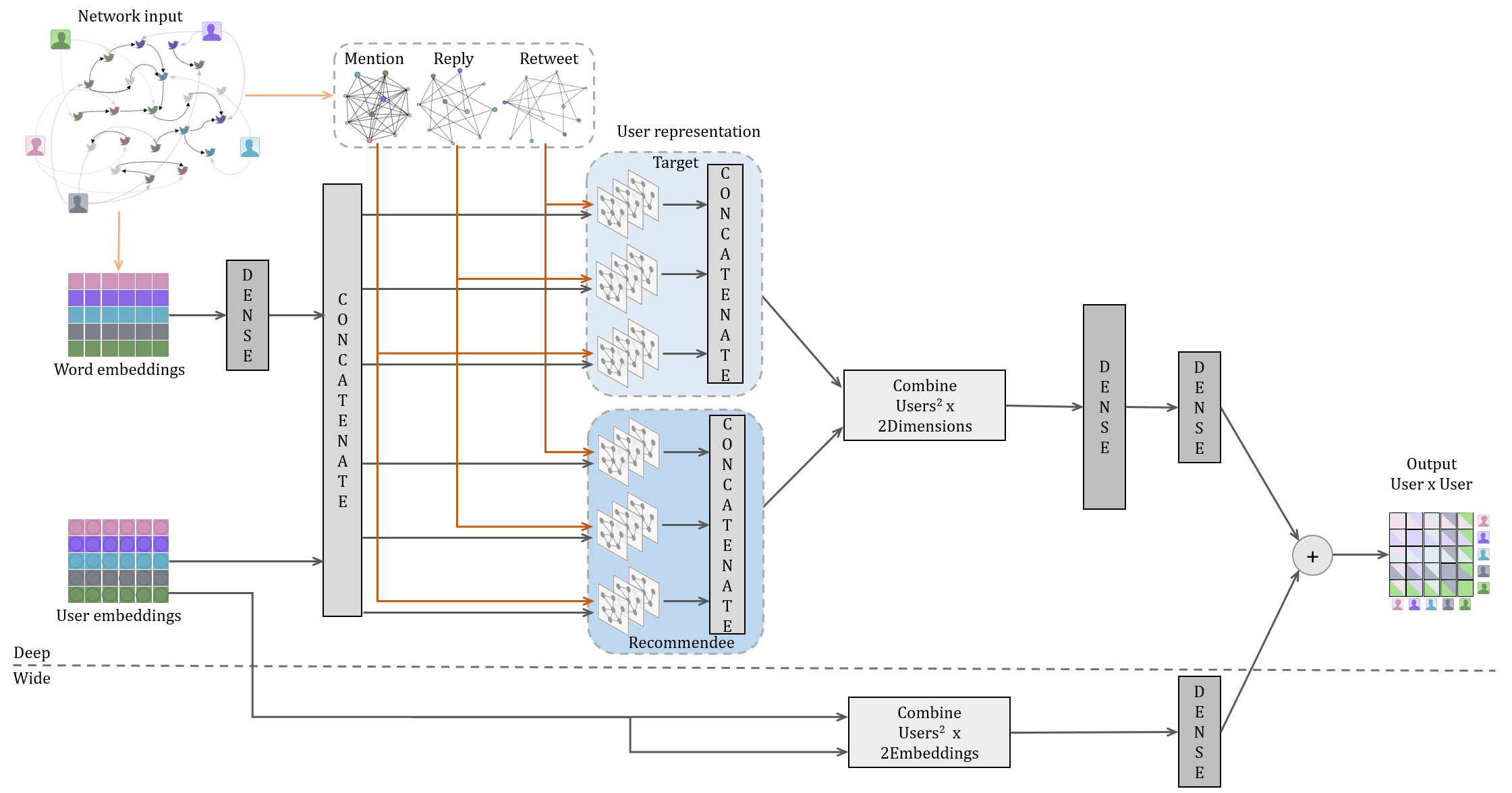
The overall architecture of FRediECH is schematized in the following figure. FRediECH takes as input users and their interactions (replies, retweets, and mentions). The output is an estimated of the relationship or interaction strength between two users. Each user is represented by an embedding of their latent features and an embedding of their tweets. FRediECH’s architecture is inspired by the Deep & Wide architecture. The Wide part bases its prediction only on the latent embeddings. On the other hand, the Deep part concatenates the latent and tweet embeddings to produce a complete user representation. These vectors are processed by two blocks of GCN layers, representing the target users and the recommendees. The outputs of each GCN are passed through two dense layers to make a prediction. Finally, the predictions of the Deep and Wide components are added to produce the final strength estimation.
Evaluation was based on the obamacare data collection, which includes tweets related to the obamacare and #aca hashtags in Twitter. The data collection also includes an estimated polarity of users sharing the tweets, based in the model in "Tweeting from left to right: Is online political communication more than an echo chamber?", in which scores allows distinguishing between democrat and republican users.
Tweets in the obamacare collection were retrieved using the Faking it!. For each tweet, we retrieve its content, user information and conversational thread (i.e, replies) and its retweets. From the original set of tweets in \texttt{obamacare}, we were able to retrieve approximately 8 million public tweets belonging to 8,164 users, and 585,524 adjacent users (users that were mentioned or replied to but that did not write any tweet on the original data collection).
Note: As per Twitter TOS, the shared graphs only include user and tweet ids involved in the interactions. No user information was included in the analysis.
Note2: The original data collection can be obtained upon request to the authors of "Political Discourse on Social Media: Echo Chambers, Gatekeepers, and the Price of Bipartisanship".
Note 3: The Faking it! can be used to rehydrate the tweets collection based on the ids in the graphs.
In the folder data you will find:
- Folders
trainingandtest. Each folder contains four files, one for each type of interaction (mentions, replies, retweets) and one mixing the three types.
Additional files:
df_tweets_users_created.csvtweets metadata incluidingtweet_id,user_idand date of creation. As the file containslongids, try not to open it with spredsheet software.df_user_leaning.csvusers leaning information, including theirown_leaning,leaning_mentions,leaning_retweets,leaning_replies,leaning_all. As the file containslongids, try not to open it with spredsheet software.train_ds.pickle,train_ds_no_neg_smp.pickleandtest_ds.pickleare helper files forFRediECHto avoid needing to have everything loaded into memory.embeddings-dates.h5is the embedding model to compute node distances.cos.npycontains pre-computed cosine similarity between nodes.training_tweeets.npycontains the BERT representation of training tweets.
Note: this files are stored in GDrive do to GitHub size limitations.
NetworkX was used for supporting the graphs.
id. User ID.central. Whether the node/user belongs to the largest connected component.
Example of node with attributes:
(1234567890, {'central': True})
source_id. User ID.target_id. User ID.weight. Number of interactions between the users.date,date_repliesanddate_retweets.datetime.datetimerepresenting the first date in which the users interacted.tweets_mentions,tweets_replies,tweets_retweets. List of tweets for each type of interaction.
Example of edge with attributes:
(1234567890, 9876543210, {'weight': 5, 'date': datetime.datetime(2016, 10, 11, 6, 20, 14), 'date_replies': None, 'date_mentions': datetime.datetime(2016, 10, 11, 6, 20, 14), 'date_retweets': datetime.datetime(2016, 10, 11, 6, 20, 14), 'tweets_replies': [], 'tweets_mentions': [1234567890000987, 12345678765434567, 123456787654324567], 'tweets_retweets': [12345673454324567, 9876673454324567]})
In the model folder, you can find the final FRediECH model reported in the paper.
The files are divided into groups that should be run in order.
RecSys-Part2-New-FullGraph.ipynb: Graph processing and distance pre-computation.
RecSys-Part2.5-New-NegSampling-Train-Dual.ipynb: Trains the FRediECH_dual model.RecSys-Part2.5-New-NegSampling-Train-Mentions-Retweets.ipynb: : Trains the FRediECH_mention_retweet model.RecSys-Part2.5-New-NegSampling-Train-Mentions.ipynb: Trains the FRediECH_mention model.RecSys-Part2.5-New-NegSampling-Train-No-Wide.ipynb: Trains the FRediECH_nowide model.RecSys-Part2.5-New-NegSampling-Train-NoBert.ipynb: Trains the FRediECH_nobert model.RecSys-Part2.5-New-NegSampling-Train-Replies-Mentions.ipynb: Trains the FRediECH_reply_mention model.RecSys-Part2.5-New-NegSampling-Train-Replies-Retweets.ipynb: Trains the FRediECH_reply_retwees model.RecSys-Part2.5-New-NegSampling-Train-Replies.ipynb: Trains the FRediECH_reply model.RecSys-Part2.5-New-NegSampling-Train-Retweet.ipynb: Trains the FRediECH_retweet model.RecSys-Part2.5-New-NegSampling-Train.ipynb: Trains the FRediECH model.RecSys-Part2.5-New-Train-No-Wide.ipynb: Trains the FRediECH_nowide_nons modelRecSys-Part2.5-New-Train.ipynb: Trains the FRediECH_nons model.
RecSys-Part3-New-NegSampling-Predict-Dual.ipynb: Predicts using the FRediECH_dual model.RecSys-Part3-New-NegSampling-Predict-Mentions-Retweets.ipynb: Predicts using FRediECH_mention_retweet model.RecSys-Part3-New-NegSampling-Predict-Mentions.ipynb: Predicts using FRediECH_mention model.RecSys-Part3-New-NegSampling-Predict-No-Wide.ipynb: Predicts using FRediECH_nowide model.RecSys-Part3-New-NegSampling-Predict-NoBert.ipynb: Predicts using FRediECH_nobert model.RecSys-Part3-New-NegSampling-Predict-Replies-Mentions.ipynb: Predicts using FRediECH_reply_mention model.RecSys-Part3-New-NegSampling-Predict-Replies-Retweets.ipynb: Predicts using FRediECH_reply_retwees model.RecSys-Part3-New-NegSampling-Predict-Replies.ipynb: Predicts using FRediECH_reply model.RecSys-Part3-New-NegSampling-Predict-Retweets.ipynb: Predicts using FRediECH_retweet model.RecSys-Part3-New-NegSampling-Predict.ipynb: Predicts using FRediECH model.RecSys-Part3-New-Predict-No-Wide.ipynb: Predicts using FRediECH_nowide_nons modelRecSys-Part3-New-Predict.ipynb: Predicts using FRediECH_nons model.
If you use FRediECH, please cite our work:
@inproceedings{10.1145/3460231.3474270,
author = {Tommasel, Antonela and Rodriguez, Juan Manuel and Godoy, Daniela},
title = {I Want to Break Free! Recommending Friends from Outside the Echo Chamber},
year = {2021},
isbn = {978-1-4503-8458-2/21/09},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3460231.3474270},
doi = {10.1145/3460231.3474270},
pages = {},
numpages = {},
keywords = {link prediction, echo chambers, social media, diversity, filter bubbles, social network analysis},
location = {Amsterdam, Netherlands},
series = {RecSys '21}
}
- Antonela Tommasel (antonela.tommasel@isistan.unicen.edu.ar)
- Juan Manuel Rodriguez (juanmanuel.rodriguez@isistan.unicen.edu.ar)
FRediECH is licenced under the Apache License V2.0. Copyright 2021 - ISISTAN - UNICEN - CONICET